Grand Mémoire - Analyse quantitative sur l'impact de Yuka
- 1 Introduction
- 2 Méthodologie
- 3 Observations sur l’effet des informations de Yuka
- 3.1 Premiers éléments
- 3.2 Une différence significative pour les produits “bons” et “excellents”
- 3.3 Une différence qu’on ne retrouve pas pour les produits “mauvais et médiocre”
- 3.4 Les deux groupes préfèrent les produits mieux notés
- 3.5 Une différence entre utilisateurs de l’application et les autres
- 4 Observations sur la nature de l’effet des informations Yuka
- 5 Limites méthodologiques
1 Introduction
Cet article retrace une partie du travail d’analyse quantitative réalisé lors de la production de mon mémoire de fin d’étude à Grenoble Ecole de Management. Le sujet de ce mémoire était le suivant : Quel impact a l’émergence des applications nutritionnelles sur les consommateurs ?
Ce mémoire s’est appuyé sur un travail d’analyse quantitative mais aussi qualitative avec la réalisation d’entretiens avec des utilisateurs de l’application Yuka. Dans cet article uniquement les aspects quantitatifs seront exposés. Afin d’étayer de manière complète la méthodologie je joins aux résultats et aux graphiques l’ensemble du code.
2 Méthodologie
2.1 Conception de l’enquête
Les participants à l’enquête sont affectés à un groupe traitement ou un groupe contrôle. Chaque participant précise son consentement à payer en euro pour 8 produits, 2 pour chaque tranche de produit dans l’application Yuka (mauvais, médiocre, bon et excellent). L’affectation aux groupes contrôle et traitement est aléatoire, comme pour l’ordre et le choix des produits dans chaque tranche. Le groupe traitement aura accès à l’information donnée par l’application Yuka, tandis que le groupe contrôle verra uniquement le produit. Pour informer de son consentement à payer le participant utilisera un curseur à positionner entre 0 et 5€. Le participant est informé que tous les produits présentés dans l’enquête ont un prix de marché compris entre 2 et 3 euros.
Les produits sélectionnés pour l’enquête sont les suivants :
| Catégorie | Produit 1 | Produit 2 |
|---|---|---|
| Mauvais - 1 | 2 boites de 16 biscuits Granola | 2 boites de biscuits McVities |
| Mauvais — 2 (additifs) | M&M’s | Poudre cacaotée Nesquik |
| Médiocre — 1 | Nutella | Céréales Kellogg’s Extra |
| Médiocre — 2 (additifs) | Jambon Herta | Semoule épicée Tipiak |
| Bon — 1 | Fromage de chèvre — Carrefour | Ketchup — Amora |
| Bon — 2 (additifs) | Activia au bifidus | Cookie cacao pépites — Gerblé |
| Excellent — 1 | Dessert fruitier pommes poires — Andros | Fromage blanc — Auchan |
| Excellent — 2 (bio) | Muesli bio (Jordans) | Mousline bio |
2.2 Formatage des résultats
Voici comment les données issues de l’enquête ont été manipulées afin d’être exploitables.
library(tidyverse)
library(here)
#Importation des résultats
results <- as_tibble(read.csv(here("static/data/yuka/results.csv")))
#Création du facteur contrôle / traitement
##On identifie les personnes du groupe Contrôle comme n'ayant pas répondu à une des deux questions possibles
##pour le premier produit (Mauvais - 1) avec l'identifiant de question du groupe traitement (_1),
##si au contraire ils ont répondu à ses questions ils sont dans le groupe traitement
results <- results %>% mutate(group = ifelse((is.na(X1.1.1.1_1) & is.na(X1.1.2.1_1)), "Contrôle", "Traitement"))
#Sélection des données qui nous intéresse
#Passage au format long
#Renommer colomnes sociologiques
#Création facteur catégorie en fonction du code + numérique pour l'ordre
df <- results %>% select(-X, -StartDate, -EndDate, -Status, -IPAddress, -Progress, -Duration..in.seconds.,
-Finished, - RecordedDate, -RecipientLastName, -RecipientFirstName,
-RecipientEmail, -ExternalReference, -LocationLatitude, -LocationLongitude,
-DistributionChannel, -UserLanguage) %>%
gather(starts_with("X"), key = "code", value = "euro") %>%
drop_na() %>%
select(code, group, euro, sexe = Q13, age = Q15, education = Q14, appli = Q12, faim = Q116, id = ResponseId) %>%
mutate(product = substr(code, 2,6),
category = case_when(substr(product, 1, 1) == "1" ~ "Mauvais",
substr(product, 1, 1) == "2" ~ "Médiocre",
substr(product, 1, 1) == "3" ~ "Bon",
substr(product, 1, 1) == "4" ~ "Excellent"),
category_nb = as.numeric(substr(product, 1, 1)))
#On ajoute le prix de base en magasin pour corriger lors des comparaisons
default.price <- read.csv(here("static/data/yuka/Default.price.csv"), sep = ";", dec = ",", encoding = "UTF-8") %>%
select(product = X.U.FEFF.product, name, default.price, grade, additives, additives.risk, additives.nb)
df <- left_join(df, default.price)
#Calucl du prix normalisé (rapport entre consentement à payer et prix de départ) et d'un booléen
#exprimant la décision d'achat ou non
df <- df %>% mutate(var.euro = euro / default.price,
buy = ifelse(euro == 0, FALSE, TRUE))
#Ecriture des résultats formatés
write.csv(df, here("static/data/yuka/shaped_results.csv"))
#Charge les résultats formatés
rm(df, default.price)
results <- read.csv(here("static/data/yuka/shaped_results.csv"))2.3 Démographie de l’échantillon
Dans cette partie nous analysons la démographie de l’échantillon afin de s’assurer que celui-ci est représentatif de la population étudiée.
library(kableExtra)
#Sujets individuels
subjects <- results %>% group_by(id) %>% select(id, group, sexe, age, education, appli, faim) %>% distinct()
#Préparation d'un tableau résumant les facteurs sociologiques par groupe
df <- list()
for (i in 1:4) {
df[[i]] <- as.data.frame(table(subjects$group, subjects %>% pull(i + 2))) %>% spread(key = Var2, value = Freq)
}
summary <- df[[1]] %>% left_join(df[[2]]) %>% left_join(df[[3]]) %>% left_join(df[[4]])
summary <- rbind(summary, c("Total", colSums(summary[,-1]))) %>% select(-Var1) %>%
mutate(Groupe = c("Contrôle", "Traitement", "Total")) %>%
select(Groupe, "F" = Femme, H = Homme, '0-17', '18-25', '26-40', '41-65', '66+',
Brevet = 'Brevet des collèges', 'CAP / BEP', Bac = 'Baccalauréat', 'BAC +2',
Sup = 'Licence / Master / Doctorat (ou équivalent)',
'Non', "Oui, par le passé" = 'Oui, j\'en ai utilisé une par le passé',
"Oui, aujourd\'hui" = 'Oui, j\'en utilise une pour faire mes achats')
kable(summary, format = "html", caption = "Sociologie de l\'échantillon") %>%
add_header_above(c(" " = 1, "Sexe" = 2, "Age" = 5, "Education" = 5, "Application" = 3))| Groupe | F | H | 0-17 | 18-25 | 26-40 | 41-65 | 66+ | Brevet | CAP / BEP | Bac | BAC +2 | Sup | Non | Oui, par le passé | Oui, aujourd’hui |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Contrôle | 36 | 22 | 0 | 13 | 15 | 28 | 2 | 1 | 2 | 3 | 14 | 38 | 28 | 11 | 19 |
| Traitement | 33 | 23 | 1 | 13 | 19 | 22 | 1 | 1 | 4 | 9 | 11 | 31 | 23 | 13 | 20 |
| Total | 69 | 45 | 1 | 26 | 34 | 50 | 3 | 2 | 6 | 12 | 25 | 69 | 51 | 24 | 39 |
L’échantillon indique une population avec un niveau d’éducation important, cela est à prendre en compte dans l’analyse. Une proportion importante de l’échentillon utilise ou a utilisé une application de type Yuka (environ 55%).
3 Observations sur l’effet des informations de Yuka
3.1 Premiers éléments
results.sum.cat <- results %>% group_by(category , category_nb, group) %>%
summarise(price = mean(euro),
sd = sd(euro),
var.price = mean(var.euro),
var.sd = sd(var.euro),
N = n()) %>%
mutate(var.se = var.sd / sqrt(N),
se = sd/sqrt(N))
#Graphique consentement à payer par rapport au prix de marché par catégorie de produit
ggplot(results.sum.cat, aes(x = reorder(category, category_nb), y = var.price, fill = group)) +
geom_col(position = position_dodge()) +
geom_hline(yintercept = 1, linetype = "dashed" , alpha = 0.5) +
theme_bw() +
theme(legend.position = "bottom",
plot.caption = element_text(face = "italic")) +
guides(fill = guide_legend(title = "Groupe : ")) +
labs(title = "Consentement à payer par catégorie de produit",
x = "Catégorie du produit selon Yuka",
y = "Variation prix (prix de marché = 1)",
caption = "Figure 6 : consentement à payer ajusté au prix de marché par catégorie de produit")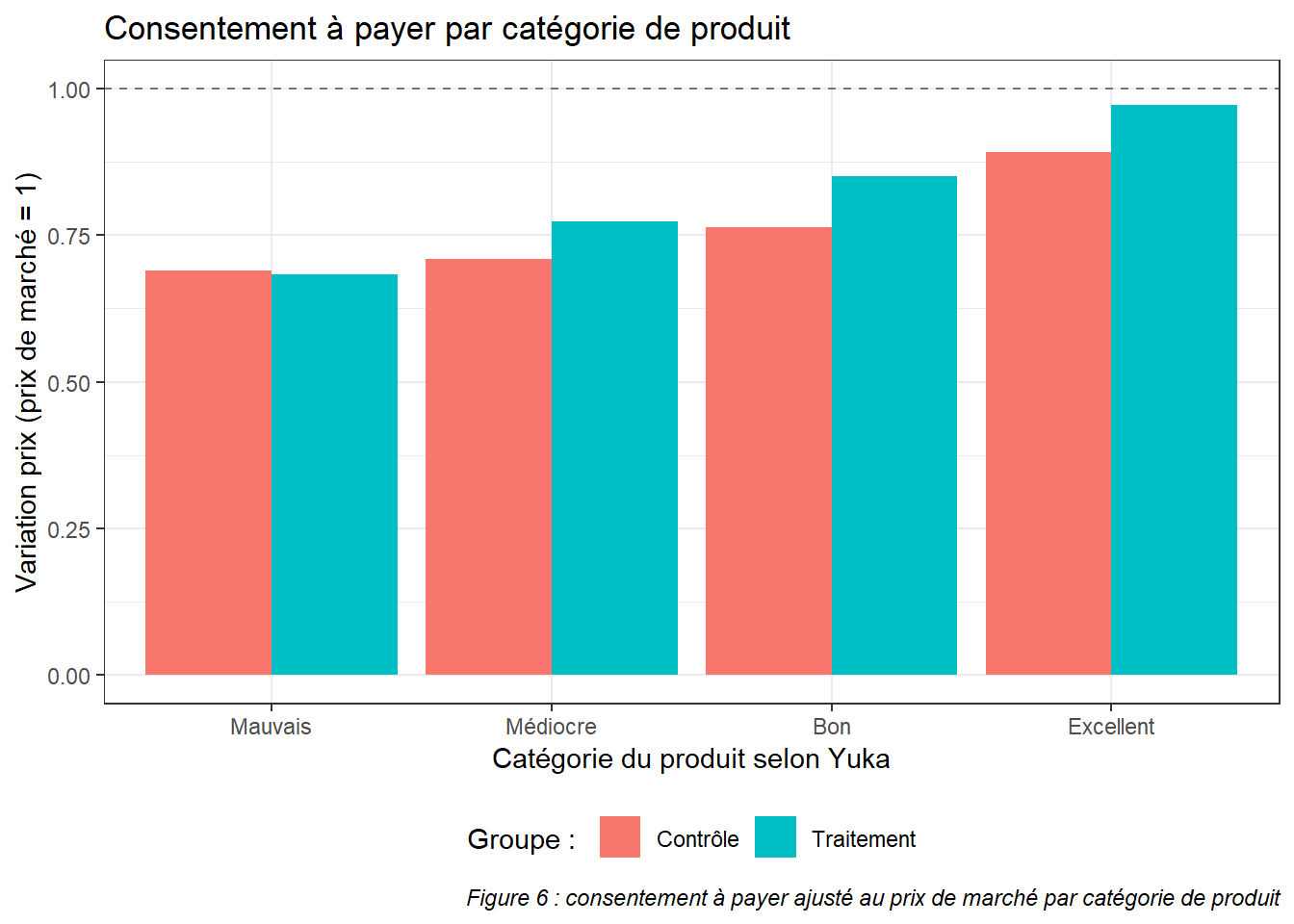
Le graphique ci-dessus (Figure 6 : consentement à payer ajusté au prix de marché par catégorie de produit) montre le consentement à payer des sujets rapporté au prix de marché. Il permet de constater les variations de consentement à payer entre le groupe contrôle et traitement en annulant l’effet prix (certains produits sont plus ou moins chers sur le marché). Ce graphique qui résume le plus simplement les résultats permet de tirer plusieurs conclusions. Pour rappel, le groupe traitement est celui qui a accès aux informations de l’application Yuka, tandis que le groupe contrôle n’a accès qu’au produit. On voit premièrement que les personnes appartenant au groupe traitement semblent prêtes à payer plus pour les produits excellents, bons et médiocres, et légèrement moins pour les produits mauvais.
3.2 Une différence significative pour les produits “bons” et “excellents”
La différence qu’on observe entre les groupes contrôle et traitement pour les produits « bons » et « excellents » est statistiquement signifiante (p-valeur < 0.05), comme montré dans l’encadré ci-dessous. Cela signifie que les répondants étant exposés aux informations de Yuka ont indiqué une propension à payer supérieure pour les produits bons et excellents, et que l’on peut généraliser cela à la population.
t.test(formula = var.euro ~ group,
alternative = "less",
data = results %>% filter(category %in% c("Bon", "Excellent")))##
## Welch Two Sample t-test
##
## data: var.euro by group
## t = -1.9063, df = 452.48, p-value = 0.02862
## alternative hypothesis: true difference in means is less than 0
## 95 percent confidence interval:
## -Inf -0.01132604
## sample estimates:
## mean in group Contrôle mean in group Traitement
## 0.8280725 0.9117399t.test(formula = var.euro ~ group,
alternative = "greater",
data = results %>% filter(category %in% c("Mauvais", "Médiocre")))##
## Welch Two Sample t-test
##
## data: var.euro by group
## t = -0.65908, df = 453.81, p-value = 0.7449
## alternative hypothesis: true difference in means is greater than 0
## 95 percent confidence interval:
## -0.1010543 Inf
## sample estimates:
## mean in group Contrôle mean in group Traitement
## 0.6995905 0.7284567On observe ainsi que l’utilisation de l’application Yuka peut inciter les consommateurs à payer plus pour les produits bien notés. Cela peut inciter les marques à proposer des produits bons pour la santé à un prix premium. Cela indique également l’efficacité potentielle de l’application pour modifier les comportements, vers l’achat de produits meilleurs pour la santé, efficacité qui sera confirmée dans la partie sur la nature de l’effet.
Tests de Welch Hypothèse alternative : les sujets exposés aux informations Yuka (traitement) sont prêts à payer plus pour les produits « bons » ou « excellents » que le groupe contrôle.
| Contrôle | Traitement | |
|---|---|---|
| Consentement à payer moyen | 0.83 | 0.91 |
| Valeur p (<0.05) | 0.029 | |
3.3 Une différence qu’on ne retrouve pas pour les produits “mauvais et médiocre”
Alors que les répondants ont ajusté leur consentement à payer à la hausse pour prendre en compte l’information positive donnée par Yuka, l’inverse n’est pas vrai. Comme le montre le graphique (figure 6), les sujets du groupe traitement n’ont pas diminué leur consentement à payer pour les produits mauvais et médiocres au vu des informations mises à leur disposition. Au contraire, les répondants du groupe traitement ont même indiqué un consentement à payer supérieur pour les produits notés médiocres. Ainsi, au contraire de notre hypothèse de départ, l’effet positif de l’application sur les bons produits semble plus marqué que celui négatif pour les produits moins bien notés. Si nous n’avons pas pu conclure de différence entre groupe traitement et contrôle sur les produits mauvais et médiocre, cela ne signifie pas qu’avec un échantillon différent, plus important ou une autre méthode, un écart statistiquement significatif ne pourra pas être décelé. Une première explication à ce résultat contre-intuitif peut être trouvée dans la partie suivante.
3.4 Les deux groupes préfèrent les produits mieux notés
On constate une différence marquée entre catégories (mauvais, médiocre, bon et excellent), quel que soit le groupe (traitement ou contrôle), comme le montre le graphique (figure 6). Ainsi, la différence entre le consentement à payer pour les produits classés comme mauvais et excellent est très significative, quel que soit le groupe observé (valeur-p < 0.01). Plus précisément, les personnes ont répondu en moyenne un consentement à payer plus proche du prix de marché pour les produits excellents. On peut donc reformuler en disant que les répondants sont prêts à payer plus pour un produit de même valeur sur le marché si sa catégorie est supérieure. Et ceci, que les catégories soient affichées ou non.
Tests de Welch
Hypothèse alternative : les sujets sont prêts à payer plus pour les produits de même valeur de la catégorie « excellent » sur Yuka par rapport aux produits de la catégorie « mauvais ».
| Contrôle | Traitement | |
|---|---|---|
| Moyenne mauvais | 0.69 | 0.68 |
| Moyenne excellent | 0.85 | 0.89 |
| Valeur p (<0.01) | 0.029 | 0.0001 |
Ce résultat est intéressant, il faut toutefois garder à l’esprit que l’enquête n’était pas conçue pour montrer cela. De ce fait, les produits présentés dans les catégories mauvais et excellent n’étaient pas directement comparables. Ainsi un effet produit pourrait être la cause de cette différence. Il indique que la qualité nutritionnelle du produit pourrait être déjà intégrée par le consommateur qui accorde son prix en fonction. Une autre étude, ou une comparaison sur un plus grand échantillon de produits sont nécessaires pour confirmer ces résultats.
Ce que semble indiquer ce résultat est que les répondants prennent en considération les qualités nutritionnelles du produit au moment d’indiquer leur consentement à payer, même sans avoir accès aux informations. Ceci est une première explication au fait que l’on n’observe pas de différence entre les personnes du groupe contrôle et traitement sur les produits mauvais et médiocre, l’influence des informations nutritionnelle est limitée, car elles sont déjà intégrées par les répondants.
3.5 Une différence entre utilisateurs de l’application et les autres
#Données regroupés par groupe, catégorie et utilisateurs d'application
results.cat.app <- results %>% group_by(appli, group, category, category_nb) %>%
summarise(price = mean(euro),
sd = sd(euro),
var.price = mean(var.euro),
var.sd = sd(var.euro),
N = n()) %>%
mutate(var.se = var.sd / sqrt(N),
se = sd/sqrt(N))
#Représentation graphique
ggplot(results.cat.app, aes(fill = group, y = var.price, x = reorder(category, category_nb))) +
geom_col(position = "dodge") +
facet_grid(rows = vars(appli)) +
theme_bw() +
theme(legend.position = "bottom",
axis.title.x = element_blank(),
plot.caption = element_text(face = "italic")) +
labs(title = "Consentement à payer moyen en fonction du statut utilisateur et de la catégorie",
y = "Variation prix (prix de marché = 1)",
caption = "Figure 7 : Consentement à payer en fonction du statut utilisateur et de la catégorie du produit") +
guides(fill = guide_legend(title = "Groupe : "))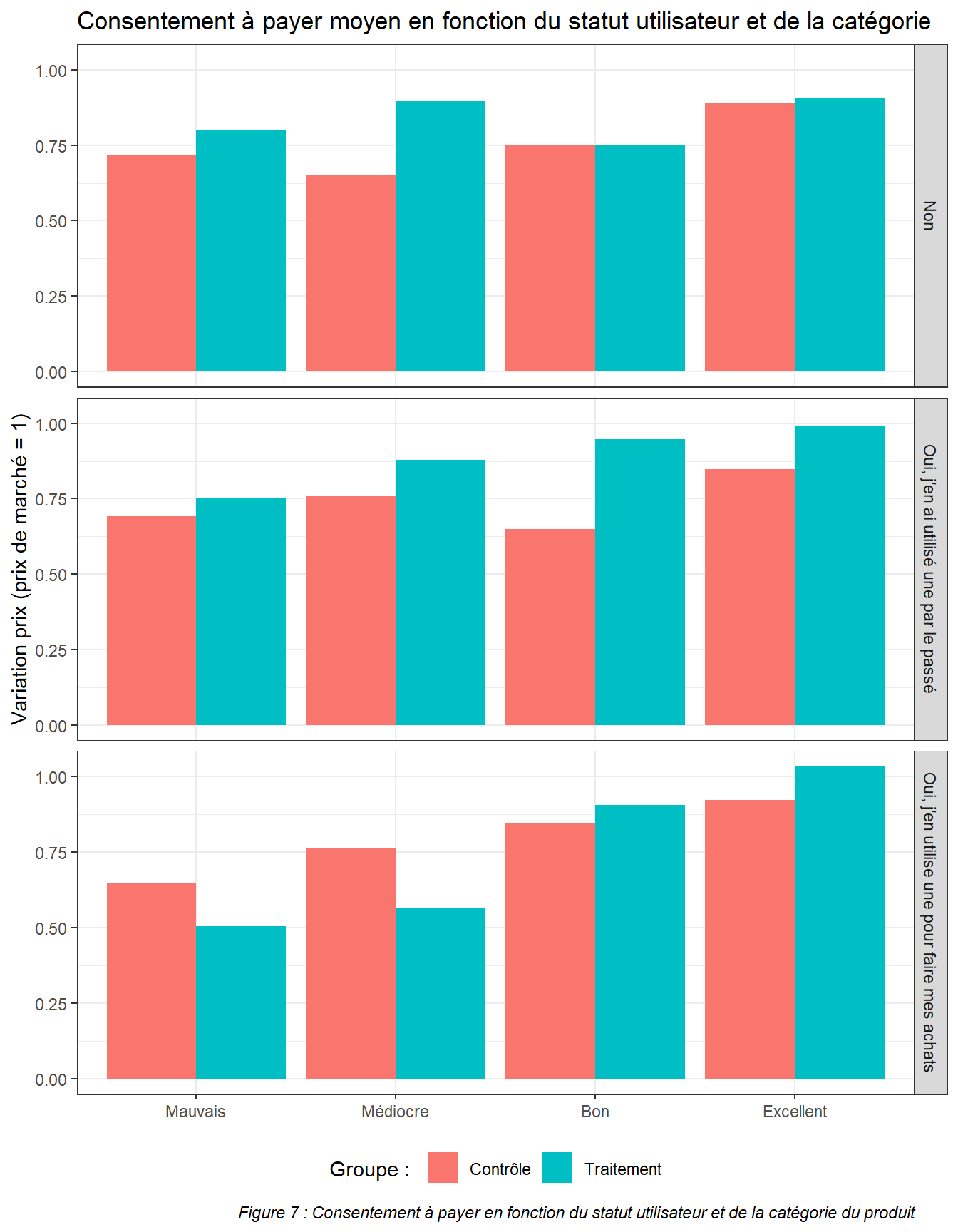
Ce graphique résume les résultats de l’enquête avec le consentement moyen à payer des sujets (par rapport au prix de marché) pour les produits des différentes catégories en fonction de leur groupe (contrôle ou traitement) et de leur utilisation d’une application comme Yuka actuelle ou passée.
Ce qu’on observe immédiatement c’est que les personnes utilisant l’application pour leurs achats ont un comportement plus proche de celui auquel on pourrait s’attendre. Ils semblent prendre en compte les informations de Yuka pour prendre leur décision à la fois en augmentant leur consentement à payer pour les produits bien notés et en le diminuant pour les produits moins bien notés.
Tests de Welch
Test 1 : produits médiocres et mauvais
Hypothèse alternative : parmi les sujets utilisant l’application pour faire leurs achats, ceux exposés aux informations Yuka (traitement) sont prêts à payer moins pour les produits « mauvais » ou « médiocres » que le groupe contrôle.
| Contrôle | Traitement | |
|---|---|---|
| Consentement à payer moyen | 0.71 | 0.53 |
| Valeur p (<0.01) | 0.008 | |
Test 2 : produits bons et excellents
Hypothèse alternative : parmi les sujets utilisant ou ayant utilisé l’application pour faire leurs achats, ceux exposés aux informations Yuka (traitement) sont prêts à payer plus pour les produits « bons » ou « excellents » que le groupe contrôle.
| Contrôle | Traitement | |
|---|---|---|
| Consentement à payer moyen | 0.84 | 0.97 |
| Valeur p (<0.01) | 0.0097 | |
On observe donc des différences très significatives (p-valeur < 0.01) sur ces utilisateurs, à la fois négative pour les produits mauvais ou médiocres, mais également positive pour les produits bons ou excellents. On observe ainsi pour les utilisateurs de Yuka la différence qu’on pensait trouver pour tous les sujets grâce à cette étude. Les utilisateurs du Yuka prennent en considération les informations de Yuka pour adapter leur consentement à payer positivement comme montré dans la partie précédente, mais également négativement. Il peut avoir deux sources à cette différence entre utilisateur ou non d’application nutritionnelle, elle explique sans doute à elles deux la différence. La première c’est que les personnes qui utilisent une application nutritionnelle sont probablement en moyenne plus intéressées par les informations que l’application ne peut leur apporter. La seconde est que les personnes utilisant l’application sont plus capables d’utiliser les informations pour modifier leur comportement, en effet, les informations étaient fournies sans aucune explication supplémentaire, les personnes n’ayant jamais utilisé d’applications nutritionnelles n’ont peut-être pas pu en tirer profit au maximum.
4 Observations sur la nature de l’effet des informations Yuka
4.1 Un effet sur la décision d’achat
Cette prochaine partie visera à déterminer comment les répondants ayant accès aux informations de Yuka modifient leur comportement. Est-ce qu’elle décide de ne pas acheter le produit mal noté ? D’acheter un produit bien noté qu’elle n’aurait pas pris autrement ? Ou est-ce qu’elle ajuste son prix vers le haut ou vers le bas ? Nous nous concentrerons sur les différences que nous avons identifiées comme statistiquement signifiantes dans la partie précédente, c’est-à-dire, pour les produits bons et excellents sur l’échantillon global, puis, sur les produits mauvais et médiocre parmi les utilisateurs de l’application.
Produits bons et excellents sur l’échantillon global
ggplot(results %>% filter(var.euro != 0, category %in% c("Bon", "Excellent")), aes(x = var.euro, fill = group)) +
geom_density(alpha = 0.5) +
theme_bw() +
labs(title = "Répartition des consentements à payer par rapport au prix de marché \nparmi les acheteurs",
y = "proportion",
x = "Rapport entre consentement à payer et prix de marché",
caption = "Figure 8 : répartition des consentements à payer par rapport au prix de marché par catégorie de produits parmi les acheteurs") +
theme(legend.position = "bottom",
plot.caption = element_text(face = "italic")) +
guides(fill = guide_legend(title = "Groupe : ")) +
facet_wrap(~reorder(category, category_nb))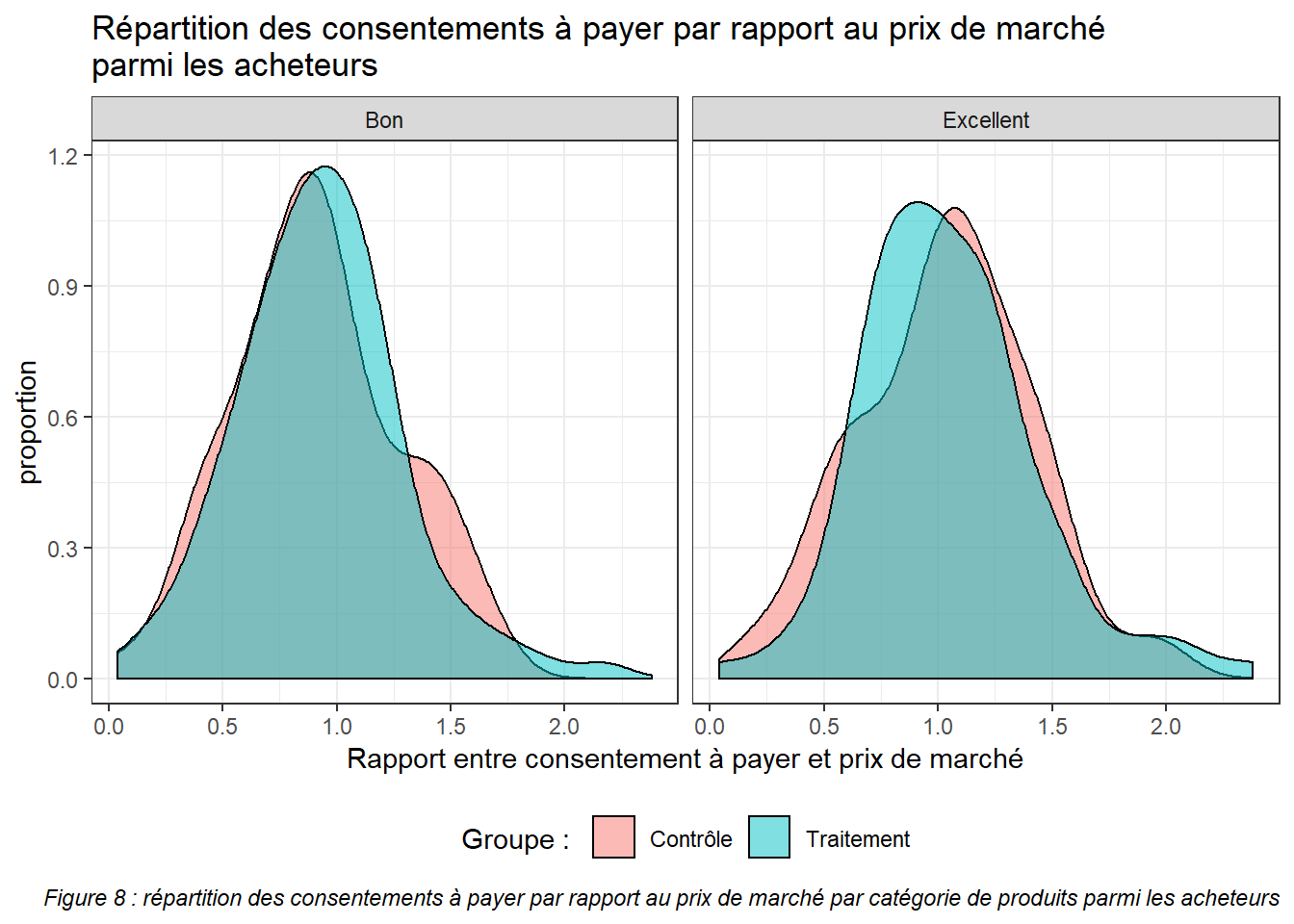
Le graphique ci-dessus montre que la répartition des consentements à payer parmi les acheteurs est relativement semblable pour les deux groupes. La différence entre les groupes contrôle et traitement ne provient donc pas d’un prix consenti différent par les acheteurs.
#Données groupés par acheteur ou non pour chaque catégorie et groupe
results.buy.cat <- results %>% group_by(group, category, category_nb) %>%
mutate(nb = n()) %>%
ungroup() %>%
group_by(group, category, category_nb, buy) %>%
summarise(prop = n() / mean(nb))
ggplot(results.buy.cat %>% filter(category %in% c("Bon", "Excellent")), aes(x = buy, fill = group, y = prop)) +
geom_col(position = "dodge2") +
facet_wrap(~reorder(category, category_nb)) +
theme_bw() +
theme(legend.position = "bottom",
axis.title.x = element_blank(),
plot.caption = element_text(face = "italic")) +
labs(title = "Part des répondants étant prêt ou non à payer pour les produits",
y = "proportion",
caption = "Figure 9 : Part des répondants qui décident d’acheter le produit") +
scale_x_discrete(labels = c("Ne souhaite pas le produit", "Prêt à acheter")) +
guides(fill = guide_legend(title = "Groupe : ")) +
scale_y_continuous(labels = scales::percent)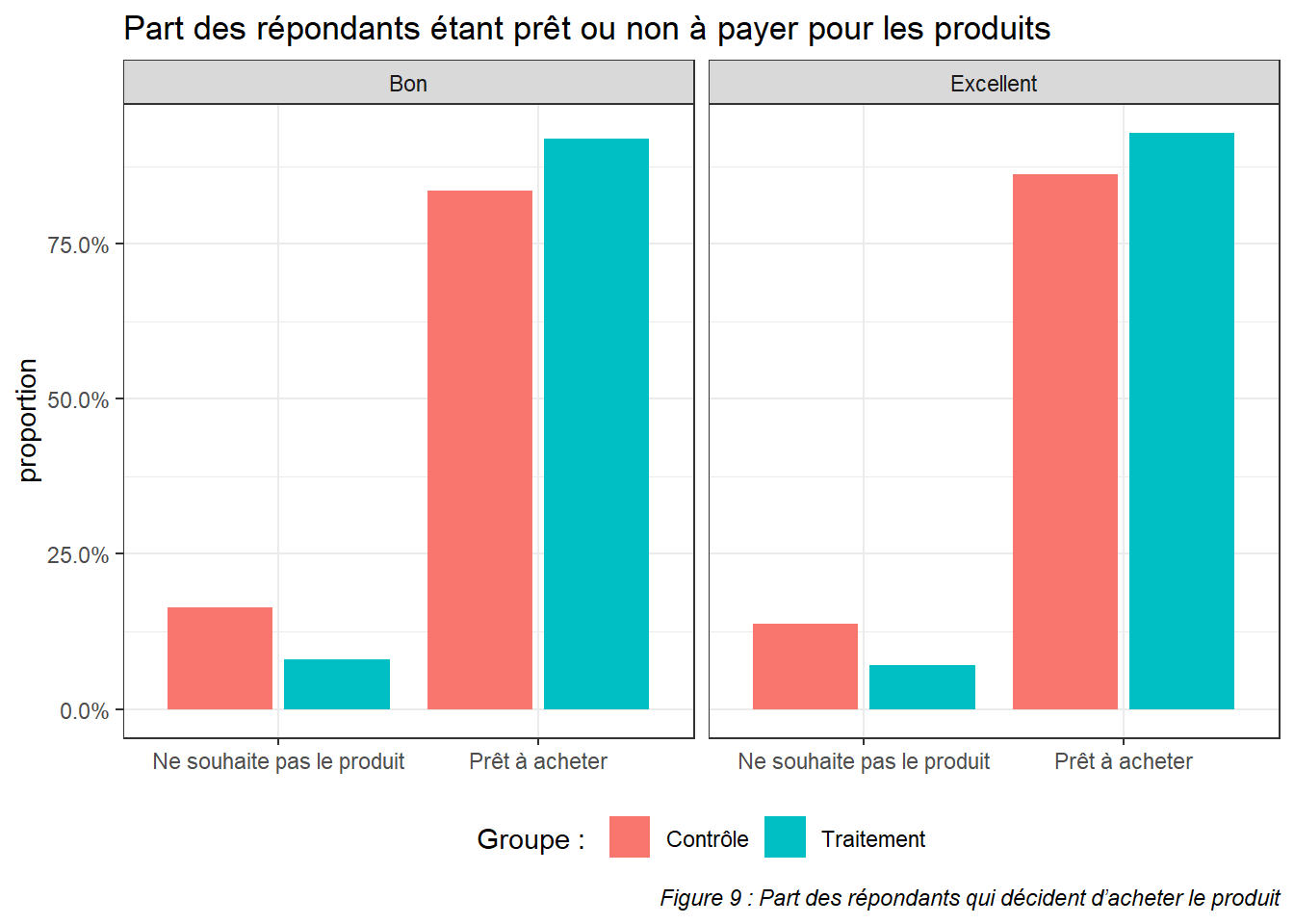
On voit en revanche sur ce second graphique que la décision d’achat est modifiée par l’information donnée par l’application. Étant donné que c’est la décision d’achat qui est modifiée et non le prix, on peut en déduire que les informations peuvent conduire les acheteurs à acheter plus de produits sains. Cette assertion n’est vérifiée que si la personne a scanné le produit. Dans l’enquête, l’information est disponible immédiatement ; or si le produit n’est pas du tout considéré par l’acheteur il pourrait ne pas le scanner.
Produits mauvais et médiocres pour les utilisateurs de l’application
Pour les utilisateurs de l’application, le constat est le même. La différence ne vient pas d’un prix d’achat inférieur pour les produits mal classés, mais d’un plus faible nombre d’acheteurs.
ggplot(results %>% filter(var.euro != 0, category %in% c("Mauvais", "Médiocre")), aes(x = var.euro, fill = group)) +
geom_density(alpha = 0.5) +
theme_bw() +
labs(title = "Répartition des consentements à payer par rapport au prix de marché \nparmi les acheteurs",
y = "proportion",
x = "Rapport entre consentement à payer et prix de marché",
caption = "Figure 10 : répartition des consentements à payer par rapport au prix de marché par catégorie de produits parmi les acheteurs utilisant une application nutritionnelle.") +
theme(legend.position = "bottom",
plot.caption = element_text(face = "italic")) +
guides(fill = guide_legend(title = "Groupe : ")) +
facet_wrap(~reorder(category, category_nb))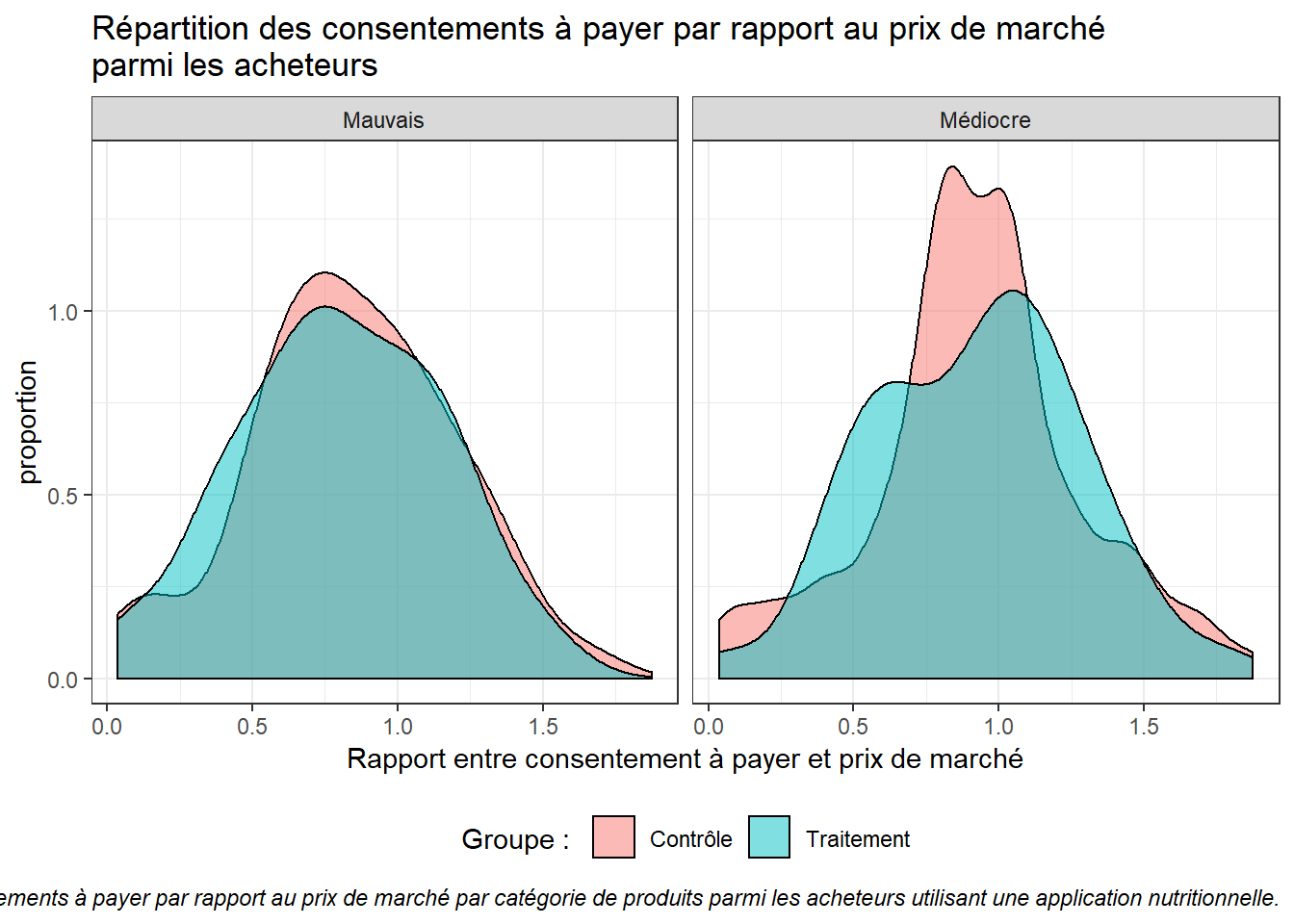
ggplot(results.buy.cat %>% filter(category %in% c("Mauvais", "Médiocre")), aes(x = buy, fill = group, y = prop)) +
geom_col(position = "dodge2") +
facet_wrap(~reorder(category, category_nb)) +
theme_bw() +
theme(legend.position = "bottom",
axis.title.x = element_blank(),
plot.caption = element_text(face = "italic")) +
labs(title = "Part des répondants étant prêt ou non à payer pour les produits",
y = "proportion",
caption = "Figure 11 : Part des répondants qui décident d’acheter le produit parmi les utilisateurs d’une application nutritionnelle") +
scale_x_discrete(labels = c("Ne souhaite pas le produit", "Prêt à acheter")) +
guides(fill = guide_legend(title = "Groupe : ")) +
scale_y_continuous(labels = scales::percent)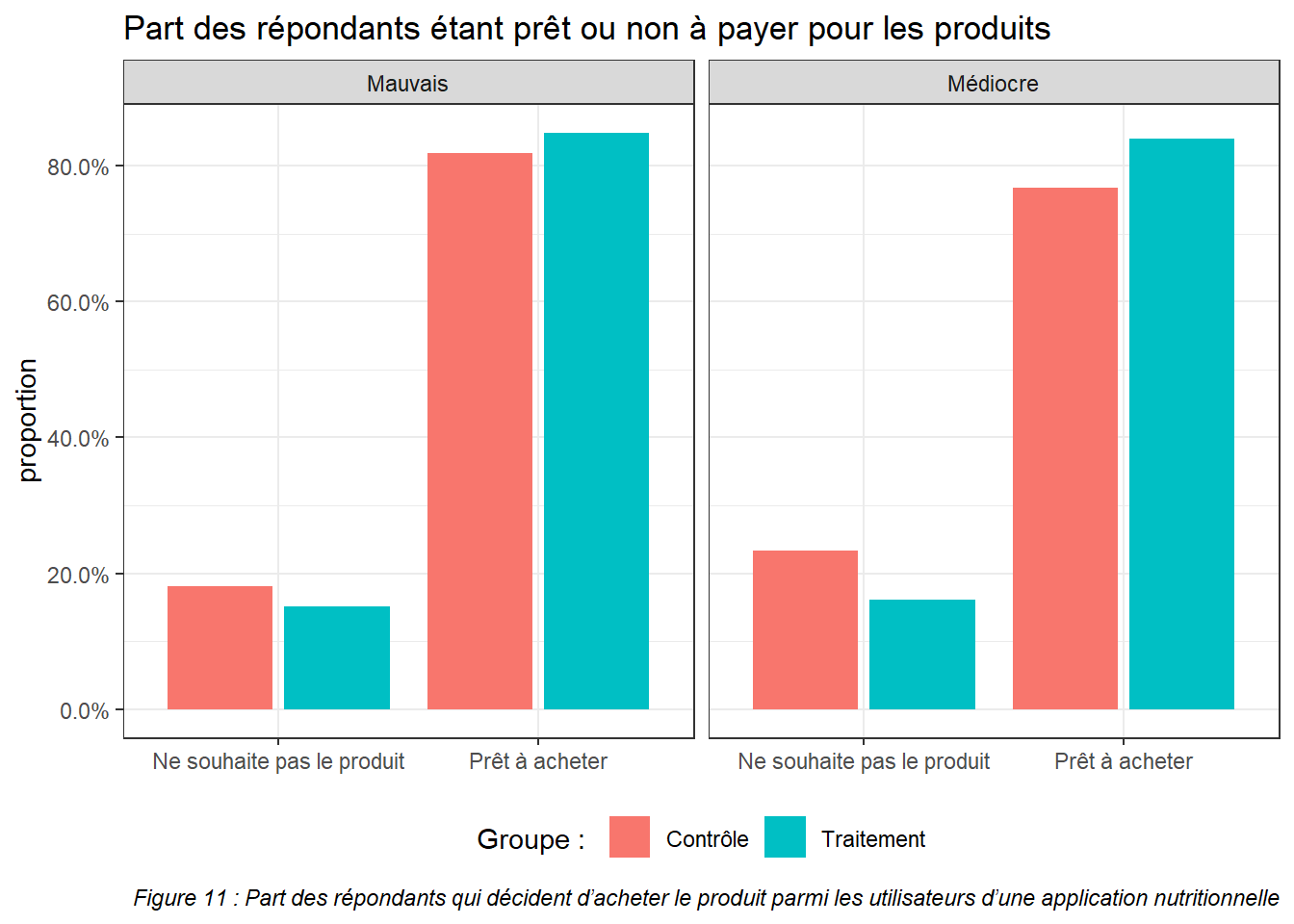
On peut donc conclure que sur cette population, l’utilisation d’application nutritionnelle permet de limiter l’achat de produits néfastes pour la santé. On constate que les utilisateurs d’applications continuent d’avoir besoin de l’information pour prendre la décision de ne pas acheter le produit.
4.2 L’effet bonne surprise
Dans notre enquête quantitative, un des produits soumis au test peut être qualifié de bonne surprise, c’est le ketchup Amora qui est classé comme bon, une catégorie peu habituelle pour un produit de ce type. Dans une moindre mesure on peut considérer que le Nutella, classé médiocre plutôt que mauvais constitue également une bonne surprise.
table_prod <- results %>% select(group, euro, category, name) %>%
group_by(group, name, category) %>%
summarise(Moyenne = mean(euro)) %>%
pivot_wider(names_from = group, values_from = Moyenne) %>%
mutate(Variation = paste0(round((Traitement / Contrôle - 1) *100, 2),"%")) %>%
arrange(desc(Traitement / Contrôle))
table_prod %>%
kable(col.names = c("Produit", "Catégorie", "Prix moyen contrôle", "Prix moyen traitement", "Variation"),
digits = 2) %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed")) %>%
row_spec(1, background = "#d7e4fa") %>%
row_spec(2, background = "#c5dafc")| Produit | Catégorie | Prix moyen contrôle | Prix moyen traitement | Variation |
|---|---|---|---|---|
| Nutella | Médiocre | 1.45 | 2.07 | 42.28% |
| Ketchup - Amora | Bon | 1.36 | 1.75 | 28.74% |
| Mousline Bio | Excellent | 1.64 | 2.07 | 26.11% |
| Cookie - Gerblé | Bon | 1.56 | 1.92 | 22.91% |
| M&M’s | Mauvais | 1.44 | 1.76 | 21.74% |
| Fromage blanc - Auchan | Excellent | 1.84 | 2.21 | 20.3% |
| Compote - Andros | Excellent | 2.01 | 2.20 | 9.61% |
| Céréales Kellogg’s Extra | Médiocre | 2.22 | 2.39 | 7.57% |
| Jambon Herta | Médiocre | 1.61 | 1.68 | 3.79% |
| Fromage de chèvre frais - Carrefour | Bon | 1.84 | 1.88 | 2.21% |
| Activia | Bon | 2.18 | 2.20 | 1.29% |
| Biscuits Granola | Mauvais | 1.99 | 2.01 | 0.87% |
| Semoule épicée Tipiak | Médiocre | 1.95 | 1.81 | -7.24% |
| Biscuits McVitie’s | Mauvais | 2.16 | 1.97 | -9.04% |
| Muesli bio - Jordans | Excellent | 2.80 | 2.46 | -12.15% |
| Poudre cacao Nesquick | Mauvais | 1.73 | 1.47 | -14.67% |
La différence se fait dans sa grande majorité, non pas par un prix plus élevé, mais par une décision d’achat supérieure. On voit sur le graphique ci-dessous (figure 12) que les répondants du groupe contrôle sont plus nombreux à ne pas acheter le produit.
ggplot(results %>% filter(name == "Ketchup - Amora"), aes(x = euro, fill = group)) +
geom_density(alpha = 0.5) +
theme_bw() +
labs(title = element_blank(),
y = "proportion",
x = "Consentement à payer en euro",
caption = "Figure 12 : distribution du consentement à payer pour le ketchup Amora") +
theme(legend.position = "bottom",
plot.caption = element_text(face = "italic")) +
guides(fill = guide_legend(title = "Groupe : ")) +
facet_wrap(facets = vars(name, category))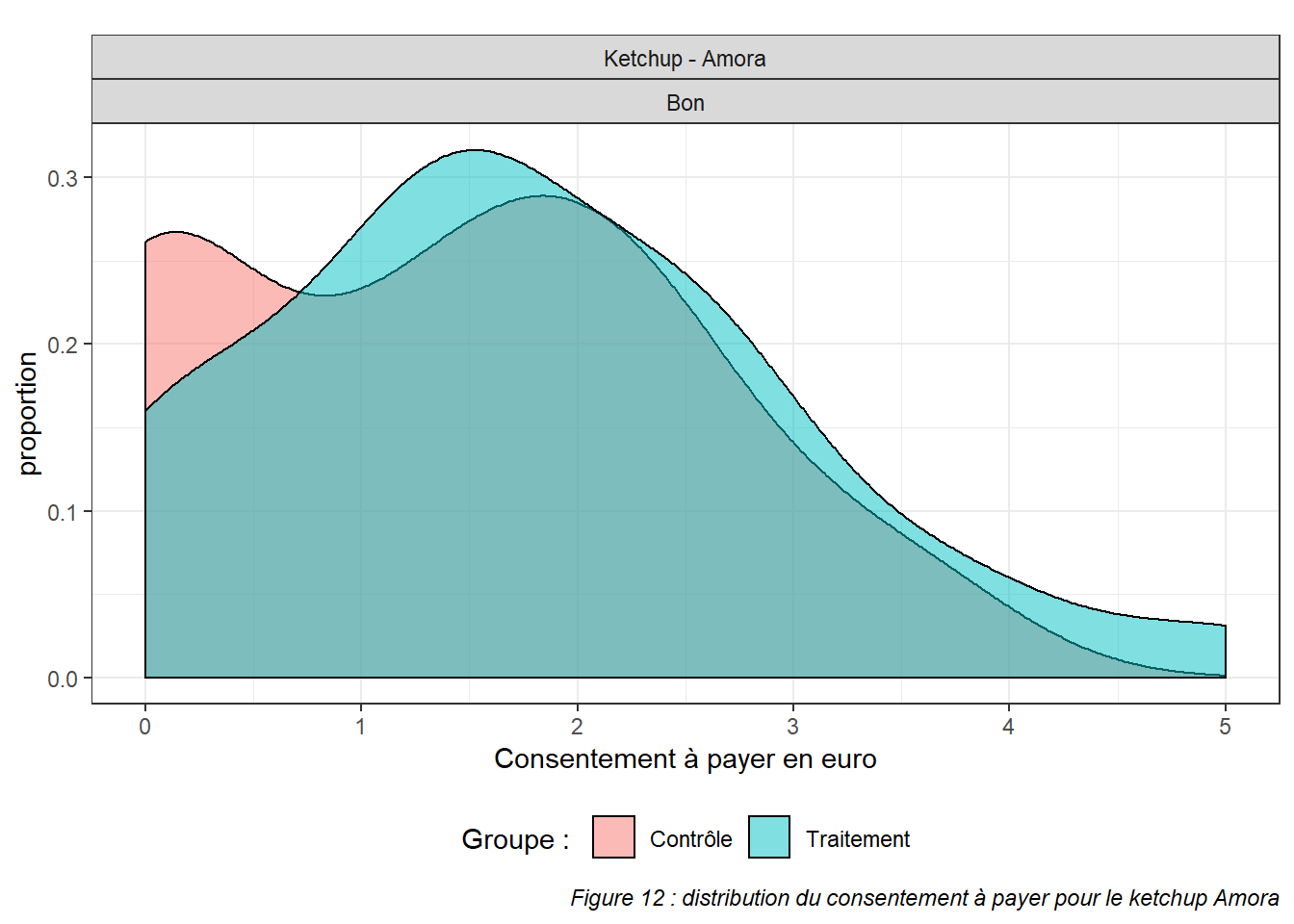
5 Limites méthodologiques
Comme expliqué auparavant, cette enquête n’a pas vocation à donner un impact précis de tel type d’information sur le consentement à payer pour un type de produit en particulier. Nous désirons explorer des pistes qui pourraient être confirmées par une étude de terrain de grande ampleur. Les produits choisis sont variés, mais limités et on ne peut pas conclure sur l’effet pour tous les produits. L’enquête ne reproduit pas fidèlement l’action du client qui scanne son produit. Le groupe traitement a l’information immédiatement. Cela crée deux différences avec la réalité aux effets opposés. Le coût de scanner le produit est supprimé (renforce l’effet), le participant n’a pas activement cherché l’information (diminue l’effet). Finalement, la différence de consentement à payer déclarée que nous pouvons observer, ne reflète pas nécessairement une différence de consentement à payer effective en magasin.
Alexis Konarski
Consultant Développement Durable
Passionné et préoccupé par les enjeux du développement durable je partage sur ce site quelques articles sur le sujet.